一、简介
TensorFlow 是一个开源的、基于 Python 的机器学习框架。由 Google 开发,并在图形分类、音频处理、推荐系统和自然语言处理等场景下有着丰富的应用,是热门的机器学习框架之一。
最初 TensorFlow 是基于 Python 的,可除了 Python,现 TensorFlow 也提供了 C/C++、Java、Go、R 等其他编程语言的接口。
为什么 TensorFlow 在 DNN 研究人员和工程师中这么受欢迎?
开源深度学习库 TensorFlow 允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 服务器、PC 或移动设备上,且只利用一个 API。那么其他深度学习库,如:Torch、Theano、Caffe 和 MxNet,和 TensorFlow 的区别在哪里?包括 TensorFlow 在内的大多数深度学习库是能够自动求导、开源、支持多种 CPU/GPU、拥有预训练模型,并支持常用 NN 架构,如递归神经网络(RNN)、卷积神经网络(CNN)和深度置信网络(DBN)。
TensorFlow 的特点:
- 支持所有流行语言,如 Python、C++、Java、R 和 Go
- 可以在多种平台上工作,包括移动平台和分布式平台
- 受到所有云服务(AWS、Google 和 Azure)支持
- Keras——高级神经网络 API,已经和 TensorFlow 整合
- 与 Torch/Theano 相比,TensorFlow 拥有更好的计算图表可视化
- 允许模型部署到工业生产,并很容易部署
- 有非常好的社区支持
- TensorFlow 不仅仅是一个软件库,还包括一套 TensorFlow,TensorBoard 和 TensorServing 软件。
一些涉及 TensorFlow 的项目:
- Google 翻译运用的是 TensorFlow 和 TPU(Tensor Processing Units)实现更准确的翻译
参考资料:http://c.biancheng.net/tensorflow/
二、下载和安装 TensorFlow
TensorFlow 可以在主流的 Linux、Mac 和 Windows 系统上使用。Ubuntu 和 MacOS 上基于 native pip、Anaconda、virtualenv 和 Docker 进行安装,在 Windows 上,可以使用 native pip 和 Anaconda。
具体安装过程不再阐述,作者很熟= =!
三、TensorFlow的HelloWorld~
在计算机语言中第一个程序都是 HelloWorld~ ,代码如下,也可以用于安装验证。
|
1 2 3 4 5 6 7 |
# Part-1 import tensorflow as tf # Part-2 message = tf.constant('Welcome to the exciting world of Deep Neural Networks!') # Part-3 with tf.Session() as sess: print(sess.run(message).decode()) |
TensorFlow 程序解读分析
前面代码分为以下三个主要部分:
- 第一部分 import 模块包含代码将使用的所有库
- 第二部分包含图形定义部分,如创建想要的计算图。上代码中就只是一个节点,tensor 常量消息由字符串构成
- 第三部分是通过会话执行计算图,这部分使用 with 关键字创建了会话,最后在会话中执行了以上计算图
一般在执行后有很多 Warning 出现,如果不想看到,可以通过下面的代码来隐蔽掉:
|
1 2 |
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' |
就是添加一个环境变量值 TF_CPP_MIN_LOG_LEVEL 设定 TensorFlow 忽略级别 2 以下的消息(级别 1 是提示,级别 2 是警告,级别 3 是错误)。
上面的程序运行表现为:打印计算图执行的结果,计算图的执行则使用 sess.run() 语句,sess.run 求取 message 中所定义的 tensor 值;计算图执行结果输入到 print 函数,并用 decode 方法改进。如果不使用 decode ,print 函数会向 stdout 输出结果:
|
1 |
b'Welcome to the exciting world of Deep Neural Networks!' |
这个输出结果是一个字节字符串。所以要删除字符串引号和 “b”(表示字节,byte) 只保留里面的内容,则需要 decode 方法。
四、TensorFlow程序结构
首先通过将程序分为两个独立的部分,构建任何拟创建神经网络的蓝图,包括计算图的定义以及计算图的执行。虽然麻烦,但正是因为分开涉及让 TensorFlow 可以在多平台上运行。
计算图:是包含节点和边的网络。定义所有要使用的数据,也就是张量(tensor)对象(常量、变量、占位符),同时定义要执行的所有计算,即运算操作对象(Operation Object,简称 OP)。
每个阶段可以有零个或多个输入,但只有一个输出。网络中的节点表示对象(张量和运算操作),边表示运算操作之间流动的张量。计算图定义神经网络的蓝图,但其中的张量还没有相关的数值。
计算图的执行:使用会话对象来实现计算图的执行。会话对象封装了评估张量和操作对象的环境。真正实现了运算操作并将信息从网络的一层传递到另外一层。不同张量对象的值仅在会话对象中被初始化、访问和保存。在此之前张量对象只被抽象定义,在会话中才被赋予实际的意义。
具体实例:
在此以两个向量相加为例设计计算图。
1. 假设有两个向量 v_1 和 v_2 将作为输入提供给 Add 操作。建立计算图:
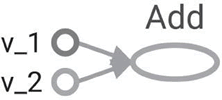
2. 定义该图的相应代码如下:
|
1 2 3 |
v_1 = tf.constant([1,2,3,4]) v_2 = tf.constant([2,1,5,3]) v_add = tf.add(v_1, v_2) # can instead of v_1 + v_2 |
3. 然后在会话执行这个“图”:
|
1 2 |
with tf.Session() as sess: print(sess.run(v_add)) |
4. 上面两行代码相当于下面的代码,但好处是不用显式写关闭会话的命令:
|
1 2 3 |
sess = tf.Session() print(sess.run(v_add)) sess.close() |
5. 运行的结果为:
|
1 |
{3 3 8 7} |
f. 每个会话都需要使用 close() 来明确关闭,而用 with 格式就不用在意使用 close() 来关闭会话了
阶段解读分析
计算图构建很简单。添加变量和操作,并按照逐层建立神经网络的顺序传递(实际就是让张量流动)。TensorFlow 还允许 with tf.device() 命令来使用具有不同计算图行对象的特定设备(CPU/GPU)。
接下来,为了使这个“图”生效,首先需要使用 tf.Session() 定义一个会话对象 sess。然后用 Session 类中定义的 run 方法运行,方法原型为:
|
1 |
run( fetches, feed_dict = None, options = None, run_metadata ) |
运算结果值在 fetches 中提取;以上面的代码为例,提取的张量为 v_add。run方法将导致在每次执行该计算图的时候,都将对 v_add 相关的张量和操作进行赋值。如果抽取的不是 v_add 而是 v_1,那么最后给出的是向量 v_1 的运行结果了。
此外,一次可以提取一个或多个张量或操作对象,如,如果结果抽取的是 [v_1 … v_add],那么输出如下:
|
1 |
{ array([1,2,3,4]), array([2,1,5,3]), array([3,3,8,7]) } |
同一段代码,可以有多个会话对象。
阶段拓展进阶
其实,上面这么多行代码可以用一行代码来实现:
|
1 |
print(tf.Session().run(tf.add(tf.constant([1,2,3,4],tf.constant([2,1,5,3])))) |
虽然一行就搞定了,但这种代码不仅影响计算图的表达,而且当在 for 循环中重复执行相同的操作时,可能会导致占用大量内存。
使用 TensorBoard 可视化图形是 TensorFlow 最有用的功能之一,特别是在构建复杂的神经网络时。构建的计算图可以在图像对象帮助菜单下进行查看。
五、TensorFlow的常量、变量和占位符
最基本的 TensorFlow 提供了一个库来定义和执行对张量的各种数学运算。张量,可以理解为一个 n 维矩阵,所有类型的数据,包括标量、矢量和矩阵等都是特殊类型的张量。
TensorFlow 支持以下三种类型的张量:
- 常量:常量是其值不能改变的张量
- 变量:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重声明为变量来实现。变量在使用前需要被显示初始化。另外,常量储存在计算图的定义中,每次加载图时都会加载相关变量。也就是说,它们是占用内存的!!!另一方面来说,变量又是分开存储的。
- 占位符:用于将值输入 TensorFlow 图中。可以和 feed_dict 一起使用来输入数据。在训练神经网络时,通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。这样在构建一个计算图时不需要真正的输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。
TensorFlow常量
声明一个标量常量或者一个标量向量:
|
1 2 3 4 5 |
// 标量常量 t_1 = tf.constant(4) // 标量向量 t_2 = tf.constant([4,3,2]) |
要创建一个所有元素为零的张量,可以使用 tf.zeros() 函数。有点和 Matlab 语言相似。这个语句可以创建一个形如 [M,N] 的零元素矩阵,数据类型(dtype)可以是 int32、float32 等:
|
1 2 3 4 5 |
tf.zeros([M,N],tf.dtype) 实例: # Results in an 2x3 array of zeros: [[0,0,0],[0,0,0]] zero_t = tf.zeros([2,3],tf.int32) |
还可以创建与现有 Numpy 数组或张量常量具有相同形状的张量常量,如:
|
1 2 3 4 5 |
# Create a zero matrix of same shape as t_2 tf.zeros_like(t_2) # Create a ones matrix of same shape as t_2 tf.ones_like(t_2) |
更进一步,还有以下语句:
- 在一定范围内生成一个从初值到终值等差排布的序列:
1tf.linspace(start,stop,num)
相应的值为 (stop-start)/(num-1) 。如:
12range_t = tf.linspace( 2.0, 5.0, 5)# We get: [2. 2.75 3.5 4.25 5.] - 从开始(默认值=0)生成一个数字序列,增量为 delta(默认值=1),直到终值(但不包括终值):
1tf.range(start,limit,delta)
举个例子:
12range_t = tf.range(10)# Result: [0 1 2 3 4 5 6 7 8 9]
Tensorflow 允许创建具有不同分布的随机张量:
- 使用一下语句创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M, N] 的正态分布随机数组:
12345t_random = tf.random_normal( [2,3], mean = 2.0, stddev = 4, seed = 12 )# Result:[[ 0.25347459 5.37990952 1.95276058],[-1.53760314 1.2588985 2.84780669]] - 创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M, N] 的截尾正态分布随机数组:
1234t_random = tf.truncated_normal( [1,5], stddev = 2, seed = 12 )# Result:[[-0.8732627 1.68995488 -0.02361972 -1.76880157 -3.87749004]] - 要在种子的 [ minval(default=0), maxval ] 范围内创建形状为 [M, N] 的给定伽马分布随机数组:
12345t_random = tf.random_uniform( [2,3], maxval = 4, seed = 12 )# Result:[[ 2.54461002 3.69636583 2.70510912],[ 2.00850058 3.84459829 3.54268885]] - 要将给定的张量随机裁剪为指定的大小:
1tf.random_crop( t_random, [2,5], seed = 12 )
其中,t_random 是一个已经定义好的张量。这将导致随机从张量 t_random 中裁剪一个大小为 [2,5] 的张量。很多时候需要以随机的顺序来呈现训练样本,可以使用 tf.random_shuffle() 来沿着它的第一维随机排列张量。
1tf.random_shuffle( t_random ) - 随机生成的张量受初始种子值的影响。要在多次运行或会话中获得相同的随机数,应该将种子设置为一个常数值。当使用大量的随机张量时,可以使用 tf.set_random_seed() 来为所有随机产生的张量设置种子。以下命令将所有会话的随机张量的种子设置为 54 :
1tf.set_random_seed(54)
TIP:种子只能为整数值
TensorFlow变量
可以通过使用变量类来创建。变量的定义还包括应该初始化的常量/随机值。
|
1 2 3 4 5 6 7 |
rand_t = tf.random_uniform( [50,50], 0, 10, seed = 0 ) t_a = tf.Variable( rand_t ) t_b = tf.Variable( rand_t ) # 将函数作为一个变量使用(所谓的变量类) # 上面创建了两个不同的张量变量t_a和t_b # 变量通常在神经网络中表示权重和偏置 |
下面的代码定义了两个变量的权重和偏置。权重变量使用正态分布随机初始化,均值为 0,标准差为 2,权重大小为 100×100。偏置由 100 个元素组成,每个元素初始化为 0。在这里也使用了可选参数名以给计算图中定义的变量命名:
|
1 2 |
weights = tf.Variable( tf.random_normal( [100,100], stddev = 2 ) ) bias = tf.Variable( tf.zeros[100], name = 'biases' ) |
前面的例子中,都是利用一些常量来初始化变量,也可以指定一个变量来初始化另一个变量。下面的语句将利用前面定义的权重来初始化 weight2:
|
1 |
weight2 = tf.Variable(weights.initialized_value(), name='w2') |
变量的定义将指定变量如何被初始化,但是必须显式初始化所有的声明变量。在计算图的定义中通过声明初始化操作对象来实现:
|
1 |
intial_op = tf.global_variables_initializer() |
每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化:
|
1 2 3 |
bias = tf.Variable(tf.zeros([100,100])) with tf.Session() as sess: sess.run(bias.initializer) |
保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:
|
1 |
saver = tf.train.Saver() |
TensorFlow占位符
除了常量和变量以外,还有一个最重要的元素——占位符,它们用于将数据提供给计算图。可以使用以下方法定义一个占位符:
|
1 |
tf.placeholder(dtype,shape=None,name=None) |
dtype 为占位符的数据类型,并且必须在声明占位符时指定。在这里,为 x 定义一个占位符并计算 y = 2 * x,使用 feed_dict 输入一个随机的 4×5 矩阵:
|
1 2 3 4 5 6 |
x = tf.placeholder( "float" ) y = 2 * x data = tf.random_uniform( [4,5], 10 ) with tf.Session as sess: x_data = sess.run( data ) print( sess.run( y, feed_dict = { x : x_data} ) ) |
阶段解读分析
需要注意的是,所有常量、变量和占位符将在代码的计算图部分中定义。如果在定义部分使用 print 语句,只会得到有关张量类型的信息,而不是它的值。
为了得到相关的值,需要创建会话图并对需要提取的张量显式使用运行命令,如:
|
1 2 3 |
print( sess.run( t_1 ) ) # Will print the value of t_1 defined in step 1 |
阶段拓展
很多时候需要大规模的常量张量对象;在这种情况下,为了优化内存,最好将它们声明为一个可训练标志设置为 False 的变量:
|
1 |
t_large = tf.Varible( large_array, trainable = False ) |
TensorFlow 被设计成与 Numpy 配合运行,因此所有的 TensorFlow 数据类型都是基于 Numpy 的。使用 tf.convert_to_tensor() 可以将给定的值转换为张量类型,并将其与 TensorFlow 函数和运算符一起使用。该函数接受 Numpy 数组、Python 列表和 Python 标量,并允许与张量对象互操作。
要注意的是,与 Python/Numpy 序列不同,TensorFlow 序列不可迭代。可以试试下面的代码,会得到一个错误的提示:
|
1 2 3 |
for i in tf.range(10) # typeError("'Tensor' object id not iterable.") |