问题
在服务器里使用显卡跑程序的时候,经常有新手甚至老手也不太清除为什么程序跑起来了,但是感觉跑的很慢,调用了GPU好像没有调用成功一样,明明程序成功运行了。
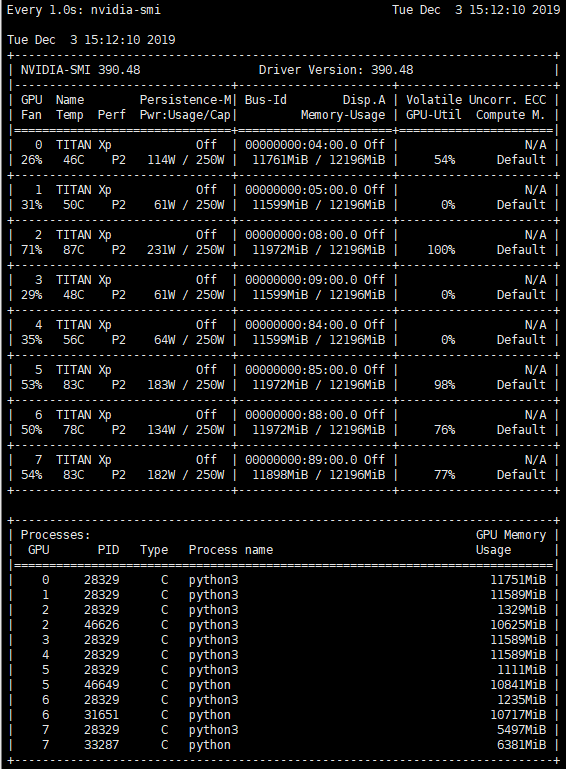
如上图,PID 为28329进程运行程序时使用的 GPU 默认占满所有可用的显卡 GPU 和 G_MEM,但只在第一个 GPU 上进行计算。虽然调用了八块显卡资源,并且占用了所有 GPU 剩下的显存,但却只有一块真正在工作,大大浪费了资源,利用率低下。
解决方法很简单,TensorFlow 有一些参数可以简单控制显卡调用数量,可以通过在运行代码前添加参数,如:
|
1 2 3 4 |
CUDA_VISIBLE_DEVIES=0,4 python3 main.py 或者在脚本里头添加代码 import os os.environ('CUDA_VISIBLE_DEVICES')='0,1' |
调用第 1 块和第 5 块显卡的资源进行运算。
但是!指定调用了显卡的 GPU 还是会完全占用指定显卡的所有显存。如上图第二号显卡,已经有别的人使用了 1329 MB,但 28329 进程很霸道的把显卡剩下的 10625 MB显存全部划走,明明都用不上!
为了不占用显卡所有的显存,还可以在创建 sess 的时候,添加参数约束调用显卡的显存量,如:
|
1 2 3 4 5 6 |
config = tf.ConfigProto(allow_soft_placement=True) # 允许根据运行时需要分配GPU内存 config.gpu_options.allow_grouth = True # 占用90%显存(优先级比上面大) config.gpu_options.per_process_gpu_memory_fraction = 0.9 sess = tf.Session(config=config) |
可是!实际上这只是解决了单 GPU 调用问题,用了合理的资源去运行我的程序而已。如果我需要用多个 GPU 去加速程序;或者运行程序需要多个显卡的 G_MEM 才能满足的时候,为了让程序可以顺利的调用多个 GPU,就需要从代码层面解决。
与 TensorFlow 的多 GPU 调用问题相比,Caffe 的多 GPU 调用问题就很简单了。Caffe 的单 GPU 切换到多 GPU 根本不需要修改任何代码,只需要在编译选项中吧 USE_NCCL 打开就可以了,剩下的都是 Caffe 自动完成。
但 TensorFlow 不一样,需要对代码有一定程度的了解,并且使用 tf.device(“/gpu:0”) 之类的代码包起来,还要注意各种变量存放的地方,各种操心,如变量放哪,怎么平均梯度,这需要对训练的过程代码非常熟悉。
- “/cpu:0” :机器的 CPU
- “/device:GPU:0” :机器的 GPU 如果只有一个
- “/device:GPU:1” :机器的第二个 GPU
TensorFlow 自己也有一些多 GPU 的示例,tutorials/image/cifar10/cifar10_multi_gpu_train.py,但也仅仅是一个 DEMO 而已,没有解释含义,换成自己的模型训练算法代码就不一定能跑起来了。
解决法:单GPU代码转为多GPU代码
利用 CUDA_VISIBLE_DEVICES 之类的方法确实可以解决一定程度的问题,但精细下来,还是会有不少的性能缺失。例如多个用户公用几块卡的时候,每个人分配不同的卡来做实验,或者每张卡上运行不同参数设置的程序(!!!),来获得线性加速比,以便在更短的时间内得到计算结果。这个时候,上面都方法就无能为力了,必须从代码层面解决了,就算可以用工程能力设置每个用户的调用量之类的方式约束,也只是会得到用户运行时因为各种资源不足而使得程序报错。(当然,貌似用集群的方法可以治一下。)
一个 MNIST 的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import tensorflow as tf from tensorflow.contrib import slim import numpy as np from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets("/tmp/mnist/",one_hot=True) # MNIST数据集存放路径 num_gpus=2 num_steps=200 learning_rate=0.001 batch_size=1024 display_step=10 num_input=784 num_classes=10 def conv_net(x,is_training): # "updates_collections": None is very import ,without will only get 0.10 batch_norm_params = {"is_training": is_training, "decay": 0.9, "updates_collections": None} #,'variables_collections': [ tf.GraphKeys.TRAINABLE_VARIABLES ] with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn=tf.nn.relu, weights_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005), normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params): with tf.variable_scope("ConvNet",reuse=tf.AUTO_REUSE): x = tf.reshape(x, [-1, 28, 28, 1]) net = slim.conv2d(x, 6, [5,5], scope="conv_1") net = slim.max_pool2d(net, [2, 2],scope="pool_1") net = slim.conv2d(net, 12, [5,5], scope="conv_2") net = slim.max_pool2d(net, [2, 2], scope="pool_2") net = slim.flatten(net, scope="flatten") net = slim.fully_connected(net, 100, scope="fc") net = slim.dropout(net,is_training=is_training) net = slim.fully_connected(net, num_classes, scope="prob", activation_fn=None,normalizer_fn=None) return net def train_single(): X = tf.placeholder(tf.float32, [None, num_input]) Y = tf.placeholder(tf.float32, [None, num_classes]) logits=conv_net(X,True) loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=logits)) opt=tf.train.AdamOptimizer(learning_rate) train_op=opt.minimize(loss) logits_test=conv_net(X,False) correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for step in range(1,num_steps+1): batch_x, batch_y = mnist.train.next_batch(batch_size) sess.run(train_op,feed_dict={X:batch_x,Y:batch_y}) if step%display_step==0 or step==1: loss_value,acc=sess.run([loss,accuracy],feed_dict={X:batch_x,Y:batch_y}) print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc)) print("Done") print("Testing Accuracy:",np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size], Y: mnist.test.labels[i:i + batch_size]}) for i in range(0, len(mnist.test.images), batch_size)])) if __name__ == "__main__": train_single() |
以上面的 MNIST 为例子,对其进行多 GPU 化改造。
多 GPU 并行可分为模型并行和数据并行两大类,我们经常用到的是数据并行的方式,而数据并行又可分为同步方式和异步方式,由于一般都会配置同样的显卡,因此这里用同步的方式,即将数据分给不同的卡,等所有的 GPU 都计算完梯度后进行平均,最后再更新梯度。
数据并行原理:模型参数保存在一个指定 GPU/CPU 上,模型参数的副本在不同 GPU 上,每次训练,提供 batch_size * gpu_num 数据,并等量拆分成多个 batch,分别送入不同的 GPU。
首先要改造的是数据读取部分,由于用到多块卡,每张卡要分到不同的数据,所以在获取 batch 的时候要把大小改为:
|
1 |
batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus) |
一次性取足够的数据保证每块卡都分到 batch_size 大小的数据。然后,对取到的数据进行切分。
|
1 2 |
_x = X[i*batch_size:(i+1)*batch_size] _y = Y[i*batch_size:(i+1)*batch_size] |
为了防止名字混乱,最好结合 name_scope 参数区分:
|
1 2 3 4 5 6 |
for i in range(2): with tf.device("/gpu:%d"%i): with tf.name_scope("tower_%d"%i): _x = X[i*batch_size:(i+1)*batch_size] _y = Y[i*batch_size:(i+1)*batch_size] logits = conv_net(_x,dropout,reuse_vars,True) |
下面是一个全代码版本模式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
import time import numpy as np import tensorflow as tf from tensorflow.contrib import slim from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("mnist/", one_hot=True) def get_available_gpus(): """ code from http://stackoverflow.com/questions/38559755/how-to-get-current-available-gpus-in-tensorflow """ from tensorflow.python.client import device_lib as _device_lib local_device_protos = _device_lib.list_local_devices() return [x.name for x in local_device_protos if x.device_type == 'GPU'] num_gpus = len(get_available_gpus()) print("Available GPU Number :"+str(num_gpus)) num_steps = 1000 learning_rate = 0.001 batch_size = 1000 display_step = 10 num_input = 784 num_classes = 10 def conv_net_with_layers(x,is_training,dropout = 0.75): with tf.variable_scope("ConvNet", reuse=tf.AUTO_REUSE): x = tf.reshape(x, [-1, 28, 28, 1]) x = tf.layers.conv2d(x, 12, 5, activation=tf.nn.relu) x = tf.layers.max_pooling2d(x, 2, 2) x = tf.layers.conv2d(x, 24, 3, activation=tf.nn.relu) x = tf.layers.max_pooling2d(x, 2, 2) x = tf.layers.flatten(x) x = tf.layers.dense(x, 100) x = tf.layers.dropout(x, rate=dropout, training=is_training) out = tf.layers.dense(x, 10) out = tf.nn.softmax(out) if not is_training else out return out def conv_net(x,is_training): # "updates_collections": None is very import ,without will only get 0.10 batch_norm_params = {"is_training": is_training, "decay": 0.9, "updates_collections": None} #,'variables_collections': [ tf.GraphKeys.TRAINABLE_VARIABLES ] with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn=tf.nn.relu, weights_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005), normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params): with tf.variable_scope("ConvNet",reuse=tf.AUTO_REUSE): x = tf.reshape(x, [-1, 28, 28, 1]) net = slim.conv2d(x, 6, [5,5], scope="conv_1") net = slim.max_pool2d(net, [2, 2],scope="pool_1") net = slim.conv2d(net, 12, [5,5], scope="conv_2") net = slim.max_pool2d(net, [2, 2], scope="pool_2") net = slim.flatten(net, scope="flatten") net = slim.fully_connected(net, 100, scope="fc") net = slim.dropout(net,is_training=is_training) net = slim.fully_connected(net, num_classes, scope="prob", activation_fn=None,normalizer_fn=None) return net def average_gradients(tower_grads): average_grads = [] for grad_and_vars in zip(*tower_grads): grads = [] for g, _ in grad_and_vars: expend_g = tf.expand_dims(g, 0) grads.append(expend_g) grad = tf.concat(grads, 0) grad = tf.reduce_mean(grad, 0) v = grad_and_vars[0][1] grad_and_var = (grad, v) average_grads.append(grad_and_var) return average_grads PS_OPS = ['Variable', 'VariableV2', 'AutoReloadVariable'] def assign_to_device(device, ps_device='/cpu:0'): def _assign(op): node_def = op if isinstance(op, tf.NodeDef) else op.node_def if node_def.op in PS_OPS: return "/" + ps_device else: return device return _assign def train(): with tf.device("/cpu:0"): global_step=tf.train.get_or_create_global_step() tower_grads = [] X = tf.placeholder(tf.float32, [None, num_input]) Y = tf.placeholder(tf.float32, [None, num_classes]) opt = tf.train.AdamOptimizer(learning_rate) with tf.variable_scope(tf.get_variable_scope()): for i in range(num_gpus): with tf.device(assign_to_device('/gpu:{}'.format(i), ps_device='/cpu:0')): _x = X[i * batch_size:(i + 1) * batch_size] _y = Y[i * batch_size:(i + 1) * batch_size] logits = conv_net(_x, True) tf.get_variable_scope().reuse_variables() loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y, logits=logits)) grads = opt.compute_gradients(loss) tower_grads.append(grads) if i == 0: logits_test = conv_net(_x, False) correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(_y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) grads = average_gradients(tower_grads) train_op = opt.apply_gradients(grads) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for step in range(1, num_steps + 1): batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus) ts = time.time() sess.run(train_op, feed_dict={X: batch_x, Y: batch_y}) te = time.time() - ts if step % 10 == 0 or step == 1: loss_value, acc = sess.run([loss, accuracy], feed_dict={X: batch_x, Y: batch_y}) print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc)+", %i Examples/sec" % int(len(batch_x)/te)) print("Done") print("Testing Accuracy:", np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size], Y: mnist.test.labels[i:i + batch_size]}) for i in range(0, len(mnist.test.images), batch_size)])) def train_single(): X = tf.placeholder(tf.float32, [None, num_input]) Y = tf.placeholder(tf.float32, [None, num_classes]) logits=conv_net(X,True) loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=logits)) opt=tf.train.AdamOptimizer(learning_rate) train_op=opt.minimize(loss) logits_test=conv_net(X,False) correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for step in range(1,num_steps+1): batch_x, batch_y = mnist.train.next_batch(batch_size) sess.run(train_op,feed_dict={X:batch_x,Y:batch_y}) if step%display_step==0 or step==1: loss_value,acc=sess.run([loss,accuracy],feed_dict={X:batch_x,Y:batch_y}) print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc)) print("Done") print("Testing Accuracy:",np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size], Y: mnist.test.labels[i:i + batch_size]}) for i in range(0, len(mnist.test.images), batch_size)])) if __name__ == "__main__": #train_single() train() |
加上前面的快捷方法,欢喜的敲入运行指令:
|
1 |
CUDA_VISIBLE_DEVICES=0,1 python3 train.py |
之后,,,,,
又双叒叕出现问题了!!!!
调用多 GPU 跑的程序竟然还比调用单 GPU 的时候跑的程序用的时间还要长!!!
还是搞不懂,等待未来的我填坑,未完待续。。。